Thanks to ByteByteGoHq:)
Architecture styles define how different components of an application programming interface (API) interact with one another. As a result, they ensure efficiency, reliability, and ease of integration with other systems by providing a standard approach to designing and building APIs. Here are the most used styles:
Definition From ByteByteGoHq
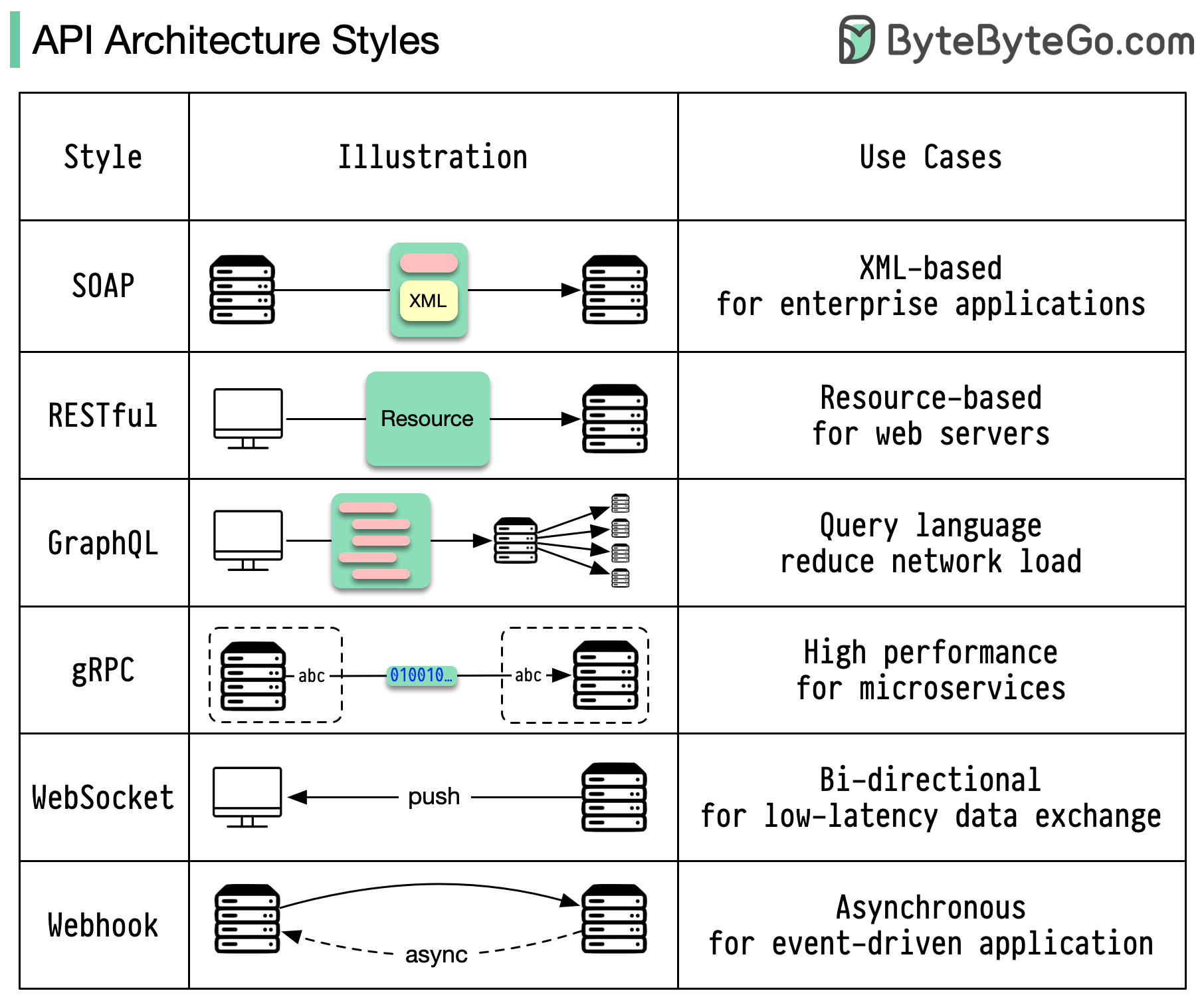
REST API vs. GraphQL
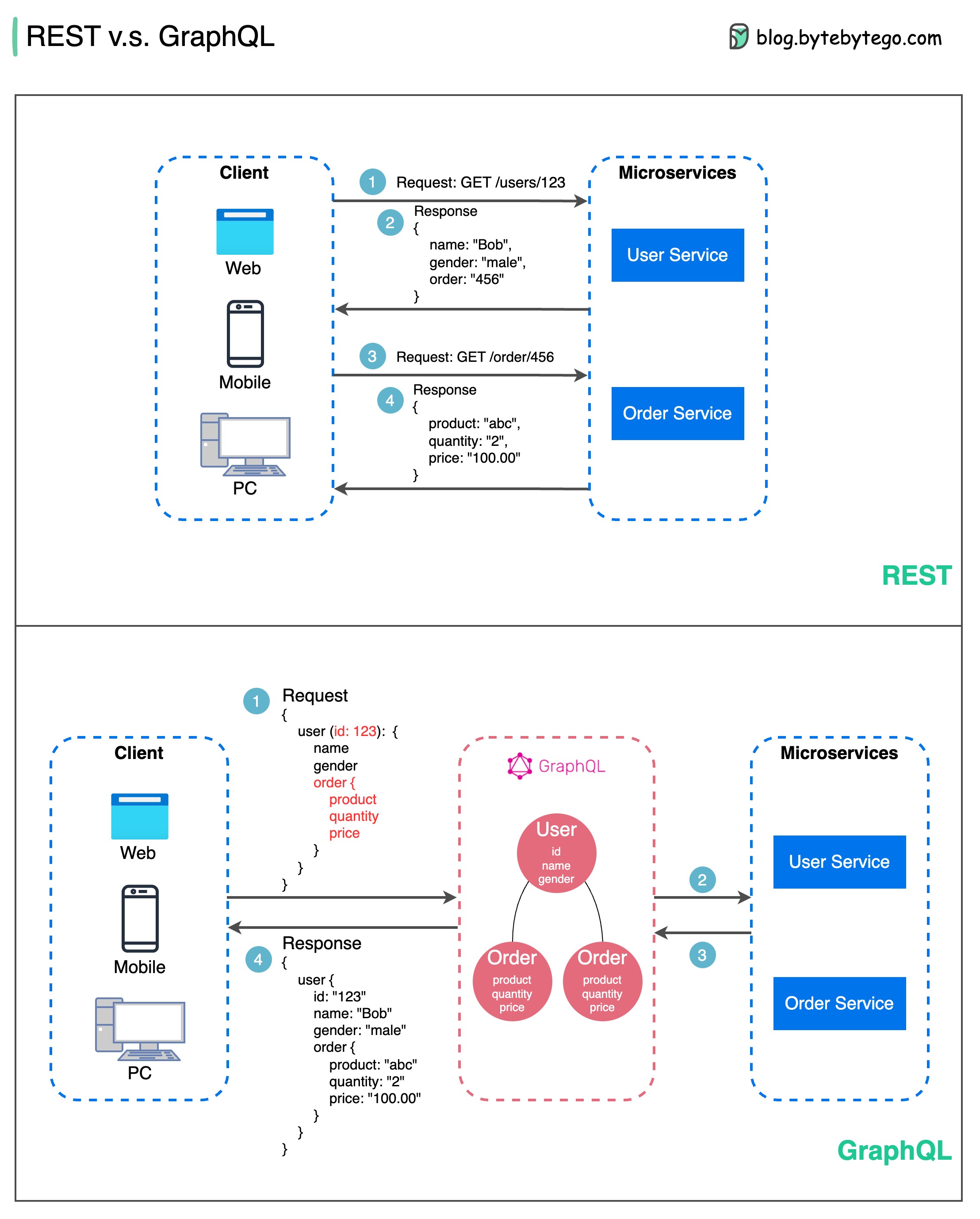
Webhook and Polling
Assume we run an eCommerce website. The clients send orders to the order service via the API gateway, which goes to the payment service for payment transactions. The payment service then talks to an external payment service provider (PSP) to complete the transactions.
There are two ways to handle communications with the external PSP.
1. Short polling
After sending the payment request to the PSP, the payment service keeps asking the PSP about the payment status. After several rounds, the PSP finally returns with the status.
Short polling has two drawbacks:
- Constant polling of the status requires resources from the payment service.
- The External service communicates directly with the payment service, creating security vulnerabilities.
2. Webhook
We can register a webhook with the external service. It means: call me back at a certain URL when you have updates on the request. When the PSP has completed the processing, it will invoke the HTTP request to update the payment status.
In this way, the programming paradigm is changed, and the payment service doesn’t need to waste resources to poll the payment status anymore.
What if the PSP never calls back? We can set up a housekeeping job to check payment status every hour.
Webhooks are often referred to as reverse APIs or push APIs because the server sends HTTP requests to the client. We need to pay attention to 3 things when using a webhook:
- We need to design a proper API for the external service to call.
- We need to set up proper rules in the API gateway for security reasons.
- We need to register the correct URL at the external service.
这张图解释了 Webhook 和 Polling 两种机制的区别。假设我们运营一个电商网站。客户端通过 API 网关向订单服务发送订单,订单服务再将订单信息传递给支付服务进行支付交易。支付服务随后与外部支付服务提供商 (PSP) 通信以完成交易。
与外部 PSP 通信有两种方式:
Polling(轮询)
客户端(你的应用)主动定期向服务端(例如支付服务商 Stripe)发起请求,询问支付是否完成。就像不断地问:“支付好了吗?支付好了吗?”。
- 优点: 实现简单,客户端可以控制请求频率。
- 缺点:
Webhook(钩子)
客户端预先向服务端注册一个回调 URL(https://myweb.com/payments/stripe)。当支付完成等事件发生时,服务端主动向该 URL 发送通知,告知客户端支付结果。就像服务端说:“支付完成了,我通知你一下”。
通过这种方式,编程范式发生了改变,支付服务不再需要浪费资源来轮询支付状态。
如果 PSP 从未回调怎么办?我们可以设置一个定时任务,每小时检查一次支付状态。
Webhook 通常被称为反向 API 或推送 API,因为是服务器向客户端发送 HTTP 请求。使用 Webhook 时,我们需要注意三点:
- 我们需要为外部服务设计一个合适的 API 接口供其调用。
- 出于安全考虑,我们需要在 API 网关中设置适当的规则。
- 我们需要在外部服务中注册正确的 URL。
整体的 webhook 的:
- 优点:
- 缺点:
两种机制的优势和区别
| 特性 | 短轮询 (Short Polling) | Webhook (网络钩子) |
|---|---|---|
| 实时性 | 低,取决于轮询频率 | 高,支付状态更新后立即通知 |
| 资源消耗 | 高,频繁的轮询消耗资源 | 低,仅在状态更新时通信 |
| 实现复杂度 | 简单 | 稍微复杂,需要设置回调 URL 和 API 接口 |
| 安全性 | 较低,外部服务直接访问支付服务 | 较高,可以通过 API 网关进行安全控制 |
| 可靠性 | 取决于轮询频率和网络状况 | 需要处理回调失败的情况,可结合定时任务提高可靠性 |
总结:
Webhook 机制通常比短轮询更高效、更实时,并且更安全。它减少了资源消耗,并提供了更及时的更新。然而,Webhook 的实现稍微复杂一些,需要设置回调 URL 和 API 接口,并需要考虑回调失败的情况。在 PSP 支持 Webhook 的情况下,Webhook 是更优的选择。如果 PSP 不支持 Webhook,或者对实时性要求不高,则可以考虑使用短轮询,但需要注意其资源消耗和安全风险。
How to improve API performance?
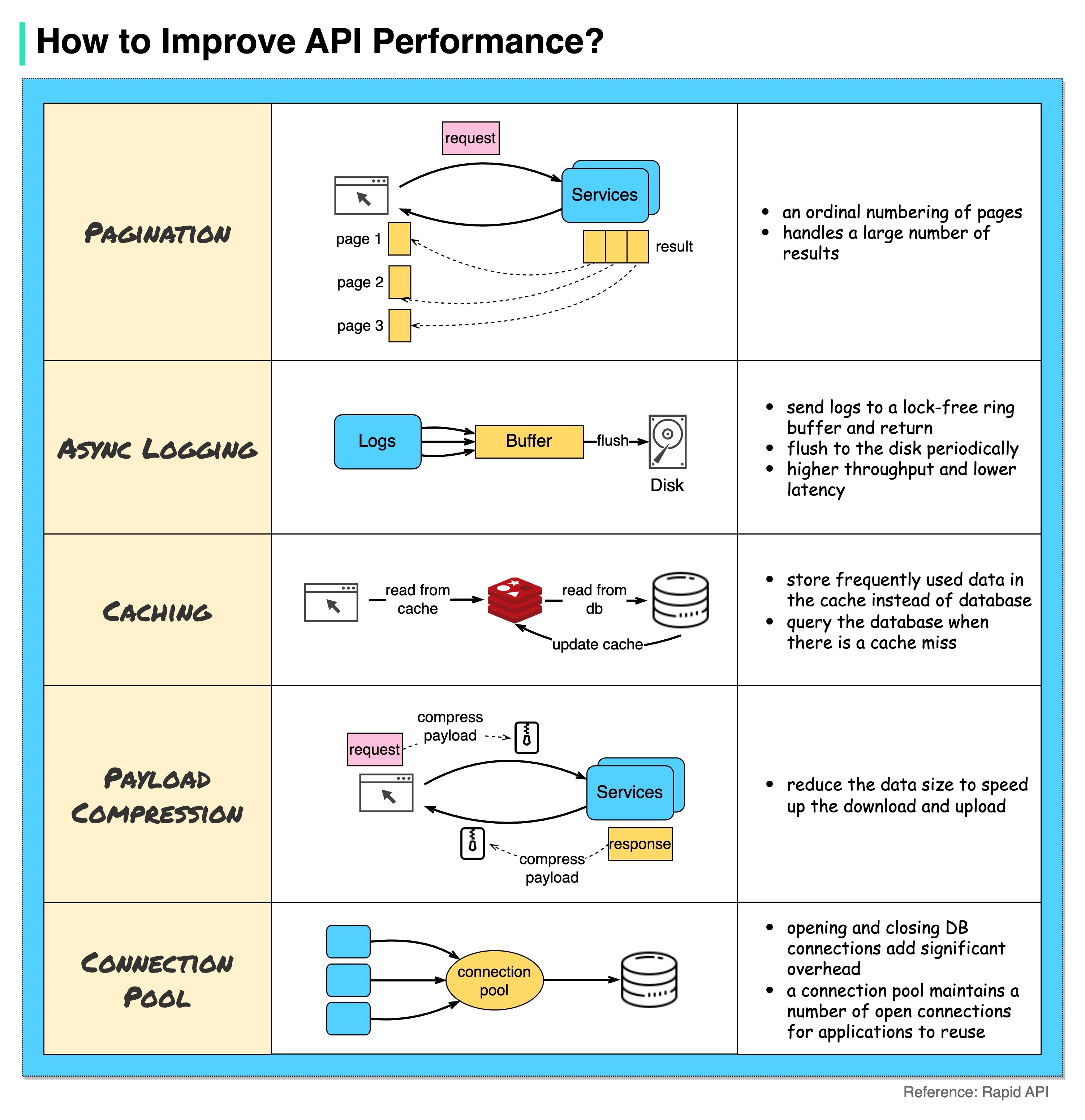
-
Pagination
This is a common optimization when the size of the result is large. The results are streaming back to the client to improve the service responsiveness.
-
Asynchronous Logging
Synchronous logging deals with the disk for every call and can slow down the system. Asynchronous logging sends logs to a lock-free buffer first and immediately returns. The logs will be flushed to the disk periodically. This significantly reduces the I/O overhead.
-
Caching
We can store frequently accessed data into a cache. The client can query the cache first instead of visiting the database directly. If there is a cache miss, the client can query from the database. Caches like Redis store data in memory, so the data access is much faster than the database.
-
Payload Compression
The requests and responses can be compressed using gzip etc so that the transmitted data size is much smaller. This speeds up the upload and download.
-
Connection Pool
When accessing resources, we often need to load data from the database. Opening the closing db connections adds significant overhead. So we should connect to the db via a pool of open connections. The connection pool is responsible for managing the connection lifecycle.
1. 分页(Pagination)
当 API 返回的结果集非常大时,分页是一种常见的优化手段。它将结果集分成多个页面,客户端每次只请求其中一页的数据。这样可以避免一次性传输大量数据,提高服务响应速度,并减少客户端的内存占用。
- 推荐应用场景: 列表接口、搜索接口等返回大量数据的场景。例如,电商网站的产品列表、社交媒体的用户列表等。
2. 异步日志记录(Asynchronous Logging)
同步日志记录每次调用都会直接写入磁盘,这会降低系统性能。异步日志记录则将日志先发送到一个无锁缓冲区,然后立即返回。日志会定期批量写入磁盘,从而显著减少 I/O 开销。
- 推荐应用场景: 对性能要求较高的场景,以及日志量较大的场景。例如,高并发接口、实时数据处理系统等。
3. 缓存(Caching)
缓存可以将经常访问的数据存储在缓存中。客户端可以先查询缓存,而不是直接访问数据库。如果缓存未命中,客户端再从数据库查询。像 Redis 这样的缓存将数据存储在内存中,因此数据访问速度比数据库快得多。
- 推荐应用场景: 读取操作频繁、数据更新频率较低的场景。例如,产品详情页、用户信息等。
4. 有效载荷压缩(Payload Compression)
可以使用 gzip 等压缩算法对请求和响应进行压缩,从而减小传输的数据量。这可以加快上传和下载速度,并减少网络带宽消耗。
- 推荐应用场景: 传输数据量较大的场景,例如,图片、视频等多媒体内容的传输。
5. 连接池(Connection Pool)
访问资源时,我们经常需要从数据库加载数据。频繁地打开和关闭数据库连接会增加显著的开销。因此,我们应该通过一个连接池来管理数据库连接。连接池负责管理连接的生命周期,复用已有的连接,避免频繁创建和销毁连接。
- 推荐应用场景: 需要频繁访问数据库的场景。例如,大多数 Web 应用和后端服务。
总结:
以上这些优化方法可以单独使用,也可以组合使用,以达到最佳的性能优化效果。选择哪种方法取决于具体的应用场景和性能瓶颈。在实际应用中,需要根据具体情况进行分析和测试,选择最合适的优化方案。
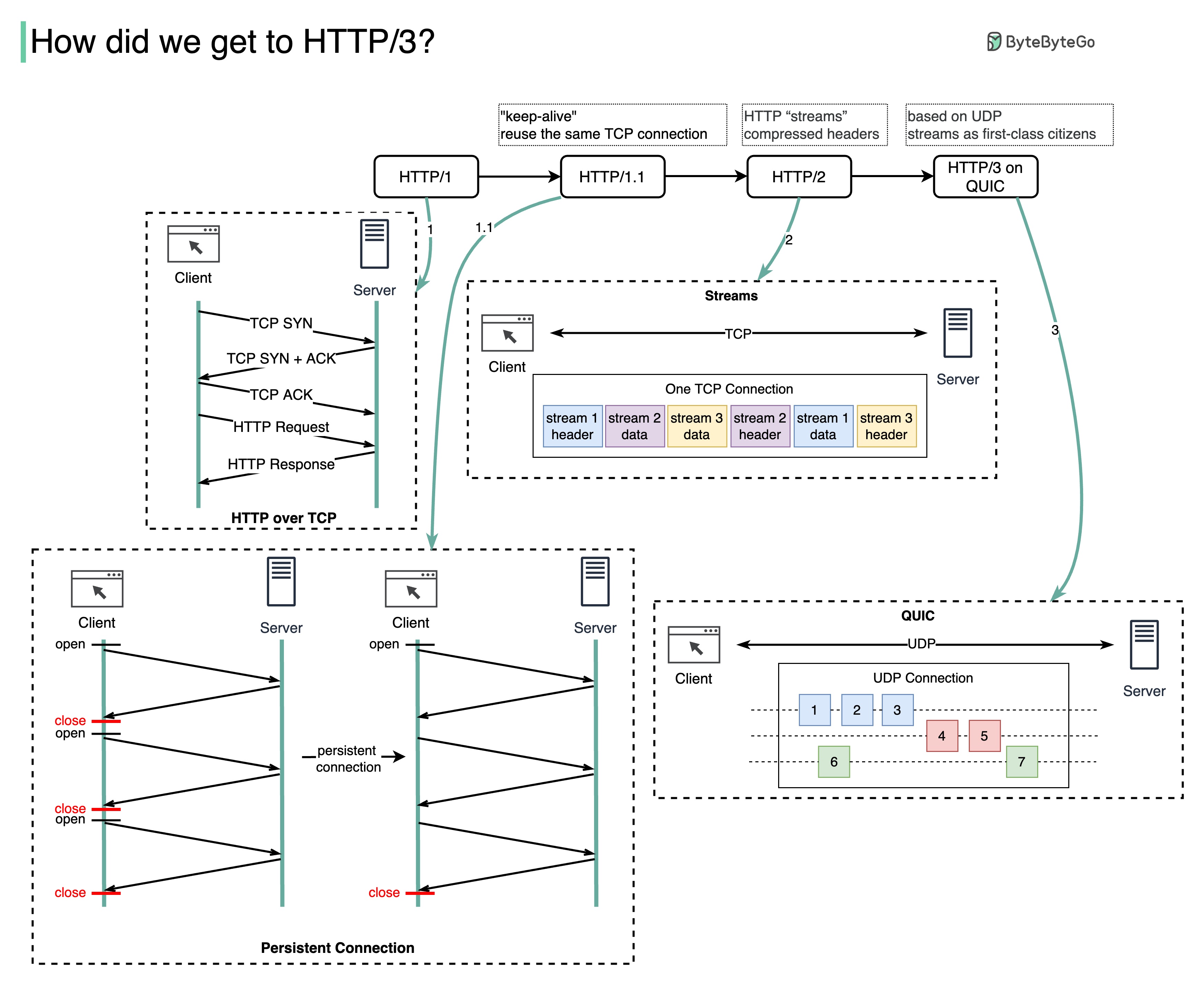
HTTP 1.0 to HTTP 1.1 to HTTP 2.0 to HTTP 3.0 (QUIC)
-
HTTP 1.0 was finalized and fully documented in 1996. Every request to the same server requires a separate TCP connection.
-
HTTP 1.1 was published in 1997. A TCP connection can be left open for reuse (persistent connection), but it doesn’t solve the HOL (head-of-line) blocking issue.
HOL blocking - when the number of allowed parallel requests in the browser is used up, subsequent requests need to wait for the former ones to complete.
-
HTTP 2.0 was published in 2015. It addresses HOL issue through request multiplexing, which eliminates HOL blocking at the application layer, but HOL still exists at the transport (TCP) layer.
As you can see in the diagram, HTTP 2.0 introduced the concept of HTTP “streams”: an abstraction that allows multiplexing different HTTP exchanges onto the same TCP connection. Each stream doesn’t need to be sent in order.
-
HTTP 3.0 first draft was published in 2020. It is the proposed successor to HTTP 2.0. It uses QUIC instead of TCP for the underlying transport protocol, thus removing HOL blocking in the transport layer.
QUIC is based on UDP. It introduces streams as first-class citizens at the transport layer. QUIC streams share the same QUIC connection, so no additional handshakes and slow starts are required to create new ones, but QUIC streams are delivered independently such that in most cases packet loss affecting one stream doesn’t affect others.
HTTP 1.0
- 解释: 这是 HTTP 的早期版本,每个请求都需要建立一个新的 TCP 连接,服务器处理完请求后立即关闭连接。1 这就像每次去商店买东西都要重新排队一样,效率很低。
- 优点: 简单易实现。
- 缺点: 性能低,由于频繁建立和关闭连接,延迟高;缺乏重要的功能,例如持久连接和 Host 头。12
- 应用场景: 由于其性能问题,HTTP 1.0 现在很少使用。
HTTP 1.1
- 解释: HTTP 1.1 引入了持久连接(persistent connection),允许在一个 TCP 连接上复用多个请求和响应。13 这就像在商店里一次购买多件商品,而不用每次都重新排队。它还支持流水线(pipelining),客户端可以连续发送多个请求,而无需等待每个响应。3 以及 Host 头,允许多个网站共享同一个 IP 地址。3
- 优点: 性能比 HTTP 1.0 好得多,减少了连接开销;支持 Host 头,方便虚拟主机。
- 缺点: 虽然流水线可以提高性能,但队头阻塞(Head-of-Line Blocking,HOL)问题仍然存在。3 如果一个请求阻塞了,后续的请求即使已经准备好,也必须等待。
- 应用场景: HTTP 1.1 仍然是目前广泛使用的协议,适用于大多数 Web 应用。
HTTP/2
- 解释: HTTP/2 通过多路复用(multiplexing)解决了 HTTP 1.1 的 HOL 阻塞问题。1 它在一个 TCP 连接上创建多个流(stream),每个流可以独立传输数据,互不干扰。这就像在商店里开设多个收银台,顾客可以并行结账。
- 优点: 显著提高了性能,消除了应用层的 HOL 阻塞;支持头部压缩,减少了数据传输量;支持服务器推送。
- 缺点: 仍然依赖于 TCP,所以 TCP 层的 HOL 阻塞问题依然存在。1 如果一个 TCP 数据包丢失,整个连接上的所有流都会受到影响。
- 应用场景: 适用于对性能要求较高的 Web 应用,例如富 Web 应用、视频流等。
HTTP/3
- 解释: HTTP/3 使用 QUIC 协议代替 TCP,从根本上解决了 HOL 阻塞问题。1 QUIC 基于 UDP,并在传输层实现了多路复用。每个 QUIC 流都是独立的,即使一个数据包丢失,也不会影响其他流。这就像每个顾客都有自己的专属通道,互不干扰。
- 优点: 彻底解决了 HOL 阻塞问题,即使在网络不稳定的情况下也能保持良好的性能;连接迁移,客户端可以在不同的网络之间切换,而不会中断连接。
- 缺点: QUIC 协议相对较新,一些旧的设备和网络可能不支持。
- 应用场景: 适用于对性能和可靠性要求极高的 Web 应用,尤其是在移动网络环境下。例如实时视频会议、在线游戏等。
HOL(Head-of-Line Blocking, HOL)
队头阻塞(Head-of-Line Blocking,HOL)是指在队列中,当队列头部的一个或多个请求被阻塞时,即使队列中后面的请求已经准备好,也无法被处理的情况。这就像在高速公路收费站,如果第一辆车因为某种原因无法通过,那么即使后面的车道是空的,后面的车辆也无法前进。
HOL 阻塞问题在网络通信中很常见,尤其是在使用 TCP 协议时。TCP 是一种面向连接的可靠传输协议,它保证数据包按顺序到达。如果一个数据包丢失或延迟,TCP 会等待该数据包重新传输或到达,在此期间,后续的数据包即使已经到达,也无法被处理,从而导致性能下降。
以下是一些 HOL 阻塞的例子:
- HTTP/1.1 流水线: 在 HTTP/1.1 中,虽然流水线技术允许多个请求同时发送,但服务器必须按顺序返回响应。如果第一个请求的响应延迟,后续请求的响应即使已经准备好,也必须等待,从而造成 HOL 阻塞。2
- TCP 层的 HOL 阻塞: 当多个数据包到达网络交换机的输入端口时,如果第一个数据包由于目标输出端口拥塞而被阻塞,那么即使后续数据包的目标端口空闲,它们也必须等待,从而造成 HOL 阻塞。1
- 负载均衡器: 如果负载均衡器将一个耗时的请求路由到后端服务器,该服务器可能会被阻塞,从而导致后续的请求即使被路由到其他空闲的服务器,也必须等待,从而造成 HOL 阻塞。1
为了解决 HOL 阻塞问题,可以使用以下一些方法:
- 多路复用: HTTP/2 和 HTTP/3 使用多路复用技术,允许多个请求和响应在同一个连接上并发传输,从而避免了 HTTP 层的 HOL 阻塞。1
- QUIC 协议: HTTP/3 使用 QUIC 协议代替 TCP,QUIC 在传输层实现了多路复用,从而避免了 TCP 层的 HOL 阻塞。1
- 多连接: 在 HTTP/1.1 中,浏览器可以通过打开多个连接来减少 HOL 阻塞的影响,但这会增加连接管理的开销。
What does API gateway do?
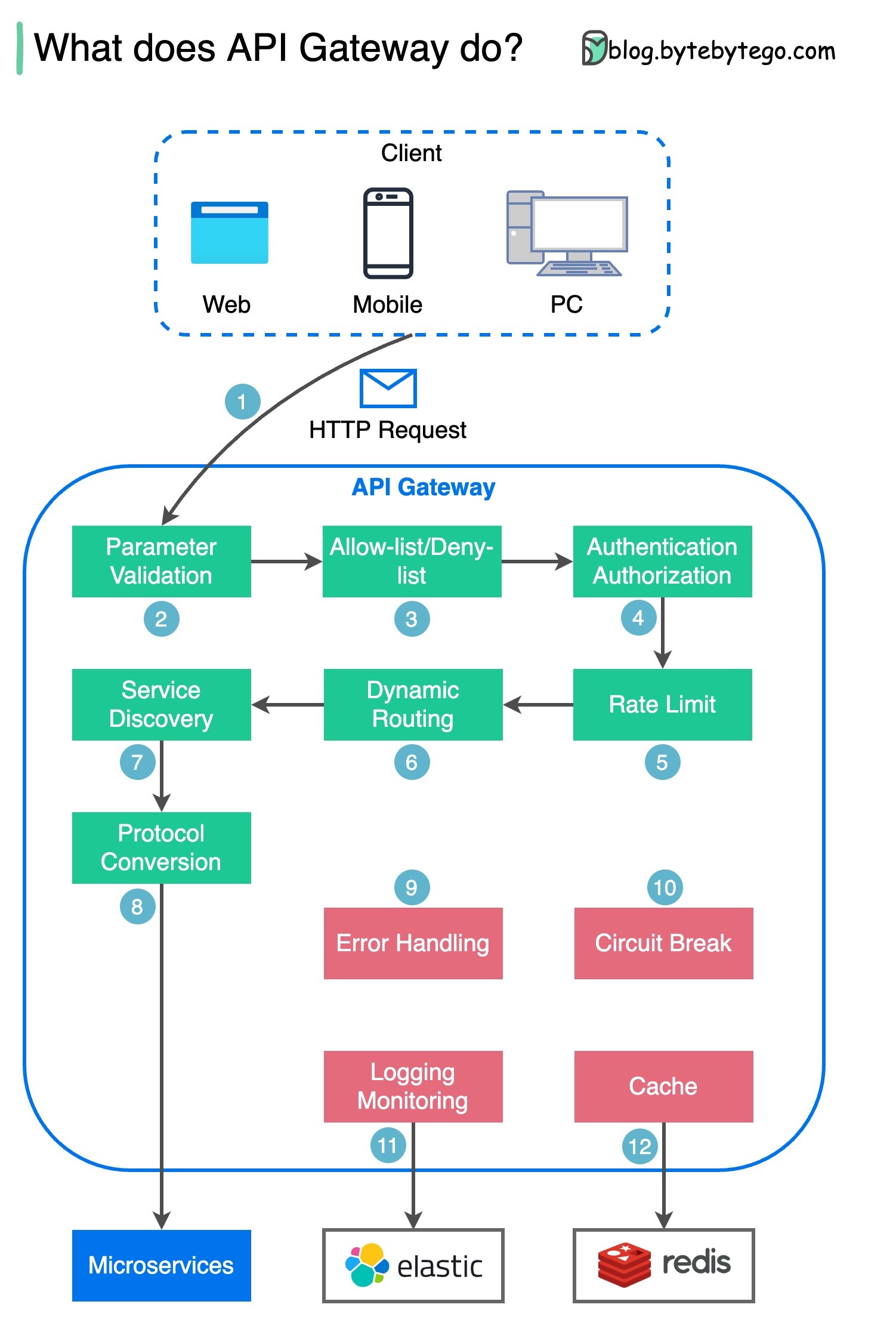
Step 1 - The client sends an HTTP request to the API gateway.
Step 2 - The API gateway parses and validates the attributes in the HTTP request.
Step 3 - The API gateway performs allow-list/deny-list checks.
Step 4 - The API gateway talks to an identity provider for authentication and authorization.
Step 5 - The rate limiting rules are applied to the request. If it is over the limit, the request is rejected.
Steps 6 and 7 - Now that the request has passed basic checks, the API gateway finds the relevant service to route to by path matching.
Step 8 - The API gateway transforms the request into the appropriate protocol and sends it to backend microservices.
Steps 9-12: The API gateway can handle errors properly, and deals with faults if the error takes a longer time to recover (circuit break). It can also leverage ELK (Elastic-Logstash-Kibana) stack for logging and monitoring. We sometimes cache data in the API gateway.
API 网关就像一个位于客户端和后端服务之间的智能反向代理和管理层。它负责接收客户端的请求,并将其路由到正确的后端服务。同时,它还执行各种重要的功能,例如身份验证、授权、速率限制和监控等,以确保 API 的安全性和可靠性。
以下是 API 网关工作流程的详细步骤,对应你提供的英文步骤:
- 客户端发送 HTTP 请求: 客户端(例如 Web 浏览器、移动应用等)向 API 网关发送 HTTP 请求。这个请求包含了客户端想要访问的资源或执行的操作的信息。
- API 网关解析和验证请求: API 网关接收请求后,会解析 HTTP 请求,检查请求的语法是否正确,并验证请求中包含的属性(例如请求头、参数等)是否有效。
- 执行允许/拒绝列表检查: API 网关会根据预先配置的允许/拒绝列表,检查客户端的 IP 地址、请求路径等是否被允许或拒绝访问 API。这有助于提高 API 的安全性,防止未经授权的访问。
- 身份验证和授权: API 网关与身份提供商(例如 OAuth 服务器、LDAP 服务器等)通信,验证客户端的身份并确定其是否有权限访问请求的资源。这确保只有经过身份验证和授权的用户才能访问 API。
- 速率限制: API 网关会根据预先配置的规则,限制客户端在特定时间段内可以发送的请求数量。这有助于防止 API 被滥用或过载,保证 API 的稳定性和可用性。如果请求超过限制,API 网关会拒绝请求。
- 路径匹配和路由: API 网关根据请求的路径,找到对应的后端服务。例如,如果请求路径是
/users,API 网关可能会将请求路由到用户服务。 - 请求转换: API 网关将客户端的请求转换为后端服务可以理解的格式。这可能涉及协议转换、数据格式转换等。例如,API 网关可以将 HTTP 请求转换为 gRPC 请求,或将 JSON 格式的数据转换为 XML 格式的数据。
- 转发请求: API 网关将转换后的请求转发到后端微服务。
- 错误处理: API 网关可以处理后端服务返回的错误,并向客户端返回友好的错误信息。这有助于提高 API 的用户体验。
- 熔断机制: 如果后端服务出现故障或长时间无法响应,API 网关可以启动熔断机制,停止向该服务发送请求,以防止级联故障。
- 日志记录和监控: API 网关可以使用 ELK(Elasticsearch、Logstash、Kibana)等工具来记录 API 请求和响应的日志,并监控 API 的性能和可用性。这有助于快速发现和解决 API 问题。
- 缓存: API 网关可以缓存常用的数据,以减少后端服务的负载,提高 API 的响应速度。
总而言之,API 网关在现代微服务架构中扮演着至关重要的角色,它简化了客户端与后端服务的交互,并提供了丰富的功能来管理和保护 API。 作为 Golang 开发者,你可以在 Kubernetes 环境中使用类似 Kong 或 Traefik 这样的 Ingress Controller 来实现 API 网关的功能。