Useful link: here
GMP 并发调度模型
Go 语言的并发模型基于 GMP 架构,这也是其高并发能力的核心:
- G (Goroutine): 轻量级线程,一段代码逻辑的执行单元
- M (Machine): 对应操作系统线程,关联到内核线程
- P (Processor): 虚拟处理器,调度器的关键部分
这三者协同工作的方式赋予了 Go 语言强大的并发处理能力 1
轻量级协程(Goroutines)
Goroutine 与传统线程相比具有显著优势:
- 极低的内存占用:初始栈空间仅 2KB(相比线程的 MB 级别)
- 动态栈大小:可根据需求自动增长和收缩,最大可达 1GB
- 创建成本低:创建一个 goroutine 只需几千字节内存
- 数量优势:单机可同时支持数十万甚至上百万个 goroutine
这种轻量级设计使得开发者可以为每个任务创建单独的 goroutine,而不必担心资源耗尽问题 4。
用户空间调度
Go 的并发调度最大特点是在用户空间完成,这带来了几个关键优势:
- 避免内核态切换:传统线程切换需要进入内核态,成本高
- 更少的上下文切换:Goroutine 切换只需保存少量寄存器状态
- 更低的调度开销:完全由 Go 运行时控制,不依赖操作系统调度
用户态调度避免了系统调用的开销,大幅提升了并发性能 5。
高效的工作窃取 (Work Stealing) 调度算法
Go 调度器采用工作窃取算法,确保处理器资源得到充分利用:
- P 会定期检查全局 runqueue,获取待执行的 goroutine
- 当 P 的本地队列为空时,会从其他 P 的队列”窃取”一半的 goroutine 来执行
- 确保负载均衡,避免某些处理器空闲而其他处理器过载
这种动态平衡机制确保了计算资源的高效利用。
系统调用处理机制
当 goroutine 执行系统调用时,Go 运行时会智能处理:
- 如果是非阻塞系统调用,goroutine 继续在当前 P 上执行
- 如果是阻塞系统调用,会将 P 与 M 分离,交给其他 M 使用
- 系统调用完成后,goroutine 被放回队列等待下一次调度
这种机制确保系统调用不会阻塞整个调度器,其他 goroutine 仍能继续执行。
通道 (Channel) 的高效通信模型
Go 的并发哲学是”通过通信来共享内存,而不是通过共享内存来通信”:
// 通过 channel 进行协程间通信
ch := make(chan string)
go func() {
ch <- "数据传输"
}()
message := <-ch // 接收数据Channel 提供了:
- 类型安全的通信机制
- 内置的同步功能
- 避免显式锁和共享内存的复杂性
- FIFO 队列特性
完整的并发原语支持
Go 标准库提供了丰富的并发控制工具:
- sync 包:提供互斥锁、读写锁、条件变量等
- sync/atomic:提供原子操作支持
- context:用于控制 goroutine 的生命周期和传递取消信号
- select:支持多通道操作的非阻塞选择
这些工具使得复杂并发场景的实现变得简单直观。
内存模型与垃圾回收
Go 的内存模型专为并发设计:
- 自动垃圾回收,减少内存泄漏风险
- 并发垃圾回收器,最小化 STW (Stop-The-World) 时间
- 逃逸分析优化,减少堆分配
- 高效的内存分配器,适应高并发场景
这些特性使得开发者无需手动管理内存,同时保持高性能。
语言级并发支持
Go 将并发作为语言的核心特性,而非库或框架的附加功能:
go关键字简化了 goroutine 的创建- 内置的 channel 类型和操作
- 简洁的并发语法和模式
- 编译器对并发的优化和支持
这种语言级支持使得并发编程变得自然且易于理解 1。
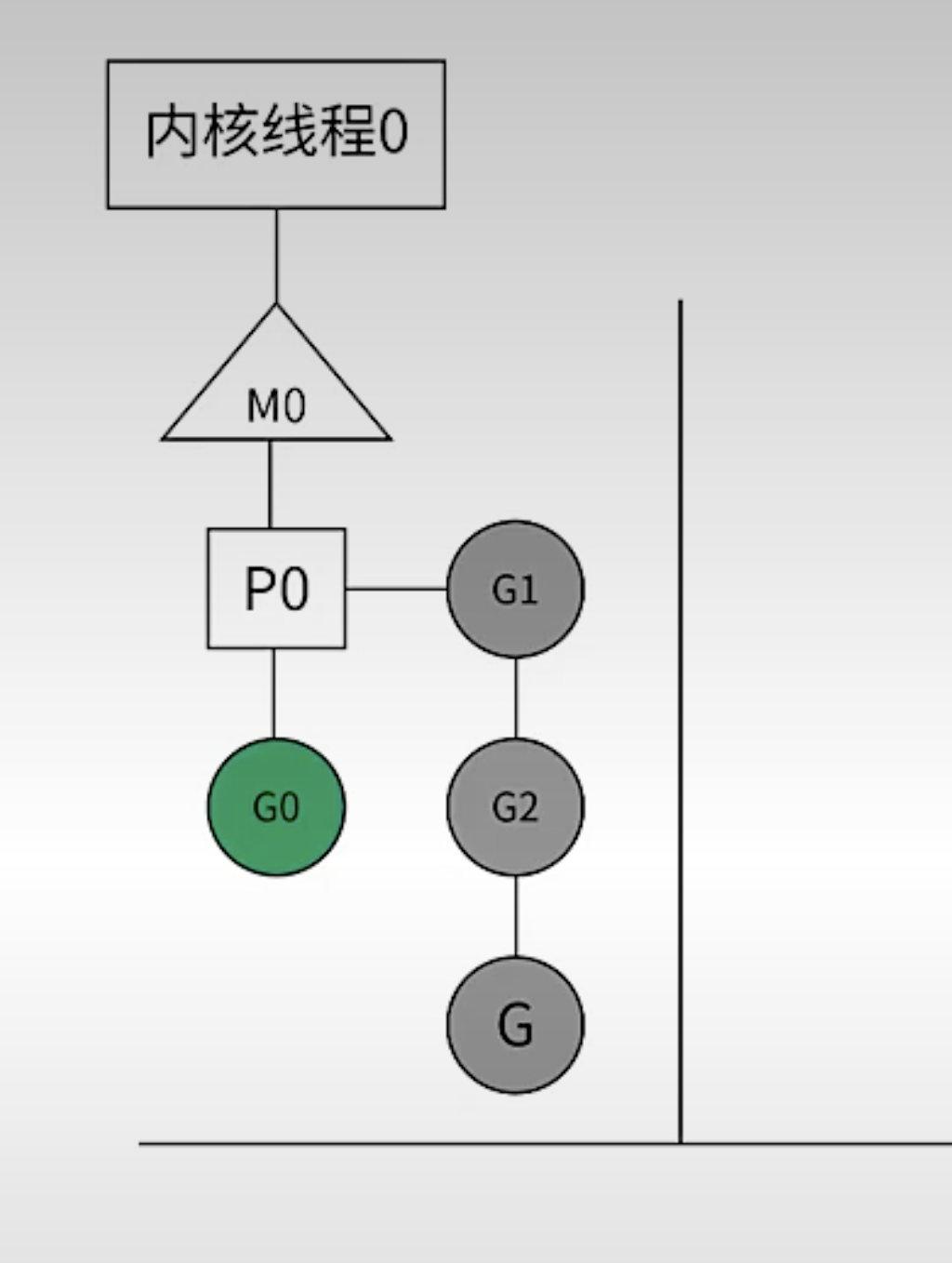
内核线程运行,服务器有几个 核心,就有几个 内核线程。
M:Machine,一台机器,内核线程下面挂了个 m0,可以把 m 想象成一个内核线程。
P:Processor,处理器,虚拟的处理器。
G:Goroutine,一段代码,一段逻辑。
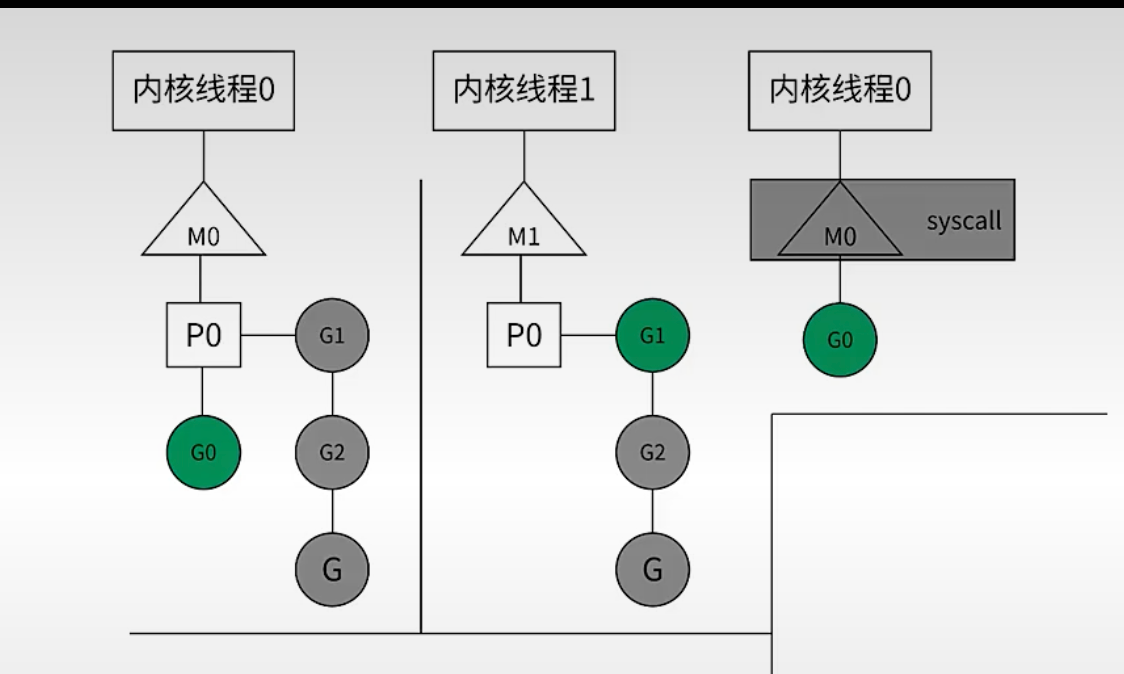
P 的数目不会超过 M,会有很多的 G,同一时间只会有一个 G 被 P 处理。其他灰色的 G 正在被阻塞中。
P 会跟 G0 解除绑定,然后 P0 带着其他的 G 找到了 内核线程 1(M1),这个时候 G1 可以继续执行。
这个时候 G0 直接挂在了 M0 中,如果 G0 搞完了,任务执行完之后,后面还有其他调用需要 P 来执行。如果有空闲的 P,可以把 G0 丢给空闲的 P。但是如果没有空闲的,那么就会被放入 runqueue。 M0 会被放入线程缓存。
runqueue 中,会多出来一些 G,这些 G 没有其他的 P 来执行。P 会定期扫描 runqueue,然后挂到自己的队列里。
此外,如果 某个 p 是空闲的,runqueue 没有空闲的 G,那么这个 p 会去其他的 p 中拿 G 来运行。
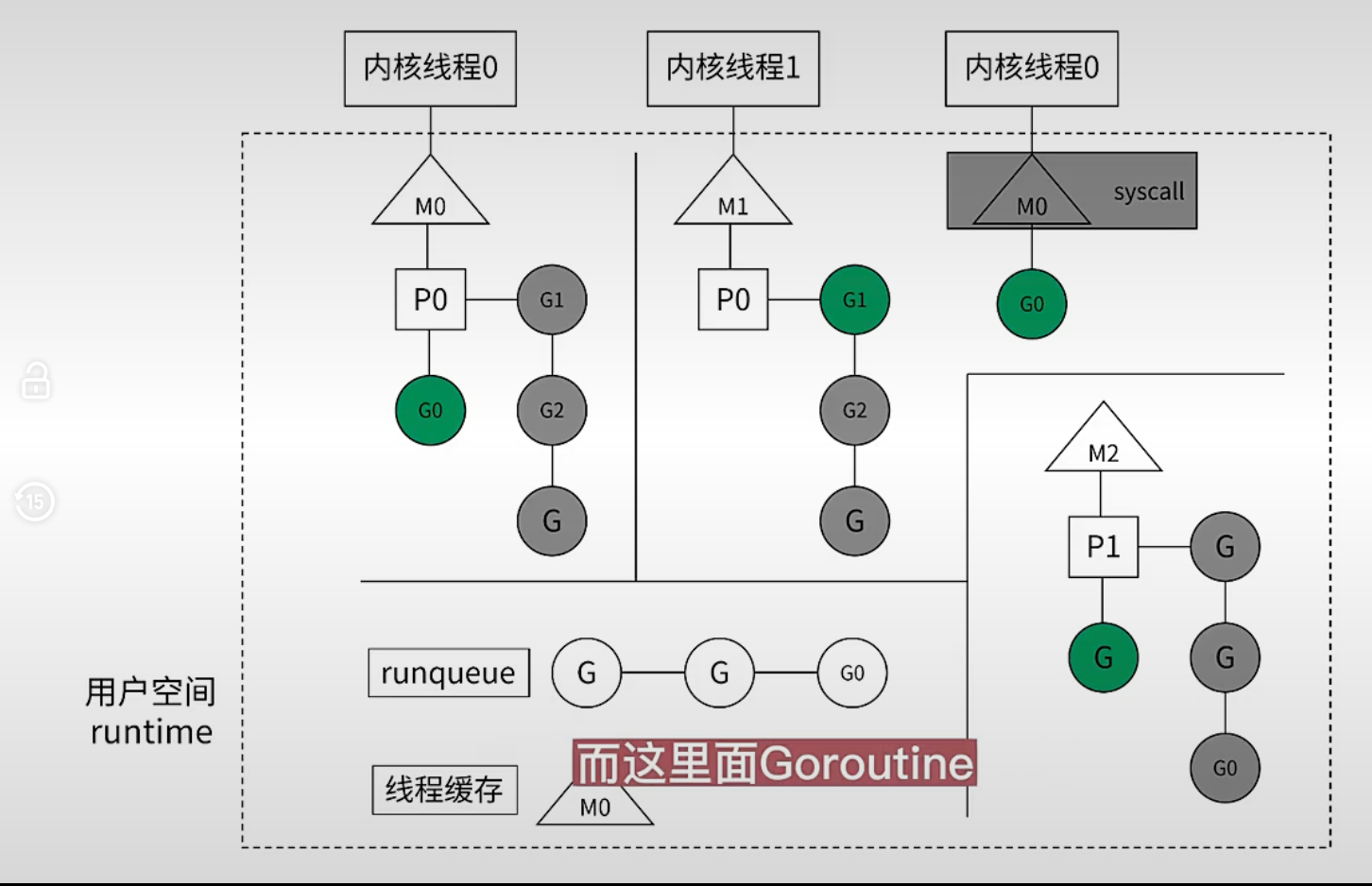
上面所有东西都在用户空间里被执行。这意味着,G 来回切换完全在 用户空间完成。常规意义上线程切换是需要内核态完成的。所以 Goroutine 的切换代价更低。
所以 Go 语言的协程比线程更加轻量的资源,切换代价更低。
这就是能够支持高并发很重要的原因
有一个关系
G1 在 G0 里产生,G0 是 G1 的父协程,但是实际上在整个调用中其实是没有关系的。
协程的切换需要保存中间状态。相比于线程切换,需要用到的寄存器比较少。内存也比较少。
理论上上百万个协程是可以的。