拿收包的过程来讲一下这件事吧。
在网络中,同步阻塞方式接收网络包的整个过程分为两部分:
-
第⼀部分是我们⾃⼰的代码所在的进程,我们调⽤的 socket() 函数会进⼊内核态创建必要内核对象。recv() 函数在进⼊内核态以后负责查看接收队列,以及在没有数据可处理的时候把当前进程阻塞掉,让出 CPU。
-
第⼆部分是硬中断、软中断上下⽂(系统线程 ksoftirqd)。在这些组件中,将包处理完后会放到 socket 的接收队列中。然后根据socket 内核对象找到其等待队列中正在因为等待⽽被阻塞掉的进程,把它唤醒。
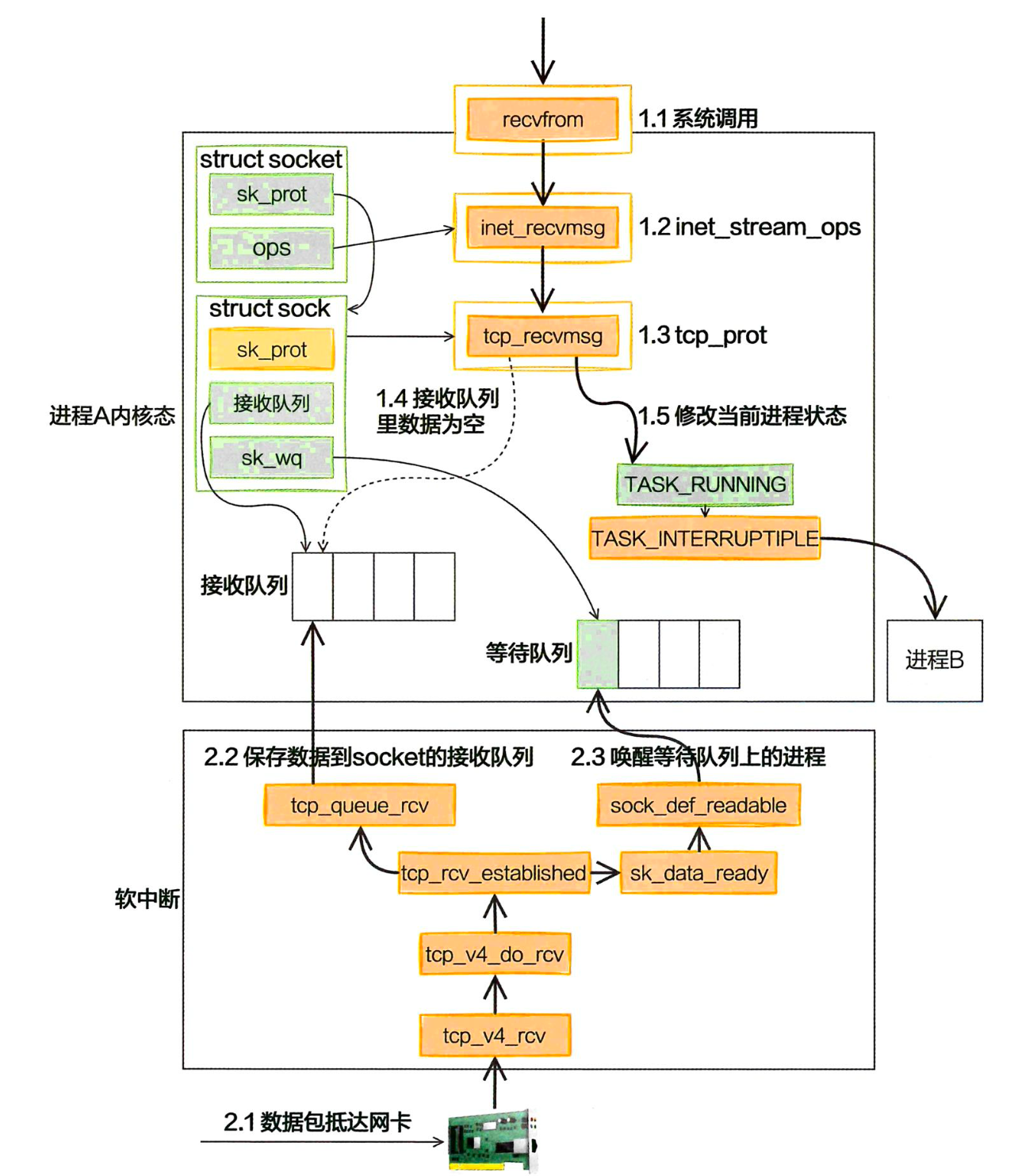
这里有一个问题,每次一个进程专门为了等一个 socket 上的数据就被从 CPU 上拿下来,然后换上另一个进程。拿到数据准备好之后,睡眠的进程又会被唤醒。
总共产生两次进程上下文切换开销。每一次切换大约花费 3 ~ 5 微妙,在不同的服务器上会有一点儿出入,但上下浮动不会太大。
这种进程上下文切换其实没有做有意义的工作。如果是网络 IO 密集型的应用,CPU 就会被迫不停地做进程切换这种无用功。
OK,回到一个服务器开发的角色视角上。我们的进程不应该有这么多等待造成的低效。因为这种简单模型里的 socket 和进程是一对一的。
现在要在单台机器上承载成千上万、甚至十几万、上百万的用户连接请求。如果用上面的方式,就得为每个用户请求都创建一个进程,这不行。
所以更高效的网络 IO 模型:select、poll 和 epoll 就出现了。
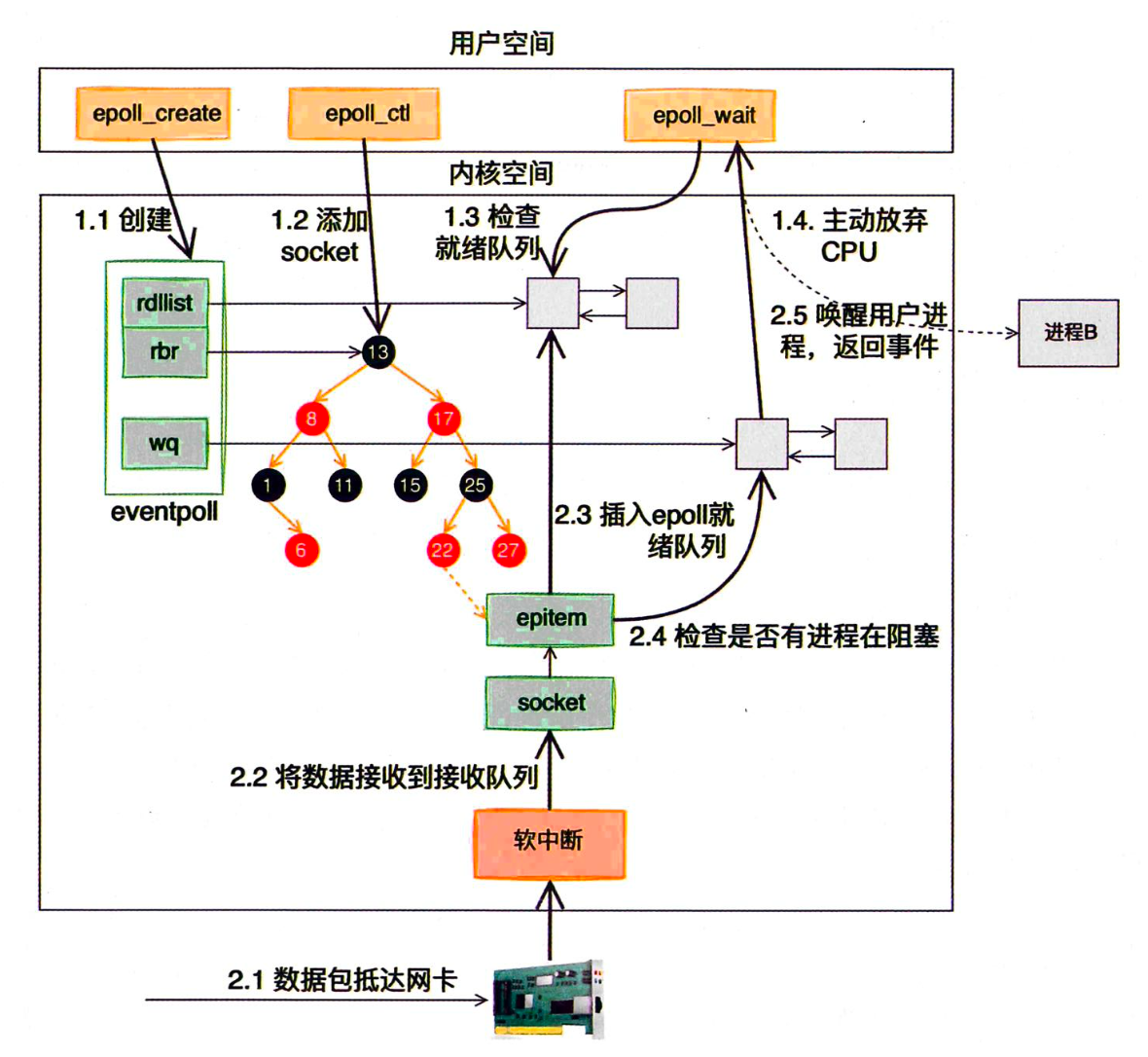
内核和用户进程协作:epoll
用户进程为了等待—个 Socket 就得被阻塞掉。进程在 Linux 上是⼀个开销不⼩的家伙,先不说创建,仅是上下⽂切换⼀次就得⼏微秒。所以为了⾼效地对海量⽤户提供服务,必须要让⼀个进程能同时处理很多 TCP 连接才⾏。现在假设⼀个进程保持了 1 万条连接,那么如何发现哪条连接上有数据可读了、哪条连接可写?
⼀种⽅法是我们可以采⽤循环遍历的⽅式来发现 IO 事件,以⾮阻塞的⽅式 for 循环遍历查看所有的 socket。 但这种⽅式太低级了,我们希望有⼀种更⾼效的机制,在很多连接中的某条上有 IO 事件发⽣时直接快速把它找出来。其实这个事情 Linux 操作系统已经替我们都做好了,它就是我们所熟知的 IO 多路复⽤机制。这⾥的复⽤指的就是对进程的复⽤。
在Linux上多路复⽤⽅案有 select、poll、epoll。 它们三个中的 epoll 的性能表现是最优秀的,能⽀持的并发量也最⼤。所以下⾯把 epoll 作为要拆解的对象,深⼊揭秘内核是如何实现多路的 IO 管理的。
epoll 原理工作流