自动化金丝雀发布是挺好的,但是其实每个阶段金丝雀的流量比例都不同,通过延长发布时间来保护生产环境,降低发生生产事故的概率。
但实际上有个致命问题:无法自动判断金丝雀环境是否出错。
这可能会导致一种情况,当金丝雀环境在接受生产流量之后,它产生了大量的请求错误,在缺少人工介入的情况下,发布仍然按照计划进行,最终导致了生产环境的故障。
为了解决这个问题,我们希望渐进式交付变得更加智能,一个好的工程实践方式是:通过指标分析来自动判断金丝雀发布的质量,如果符合预期,就继续金丝雀步骤;如果不符合预期,则进行回滚。这样,也就能够避免将金丝雀环境的故障带到生产环境中了,这种分析方法也叫做金丝雀分析。
将 Argo Rollout 和 Prometheus 结合,实现自动渐进式交付。
概述
整体架构和流程图如下:
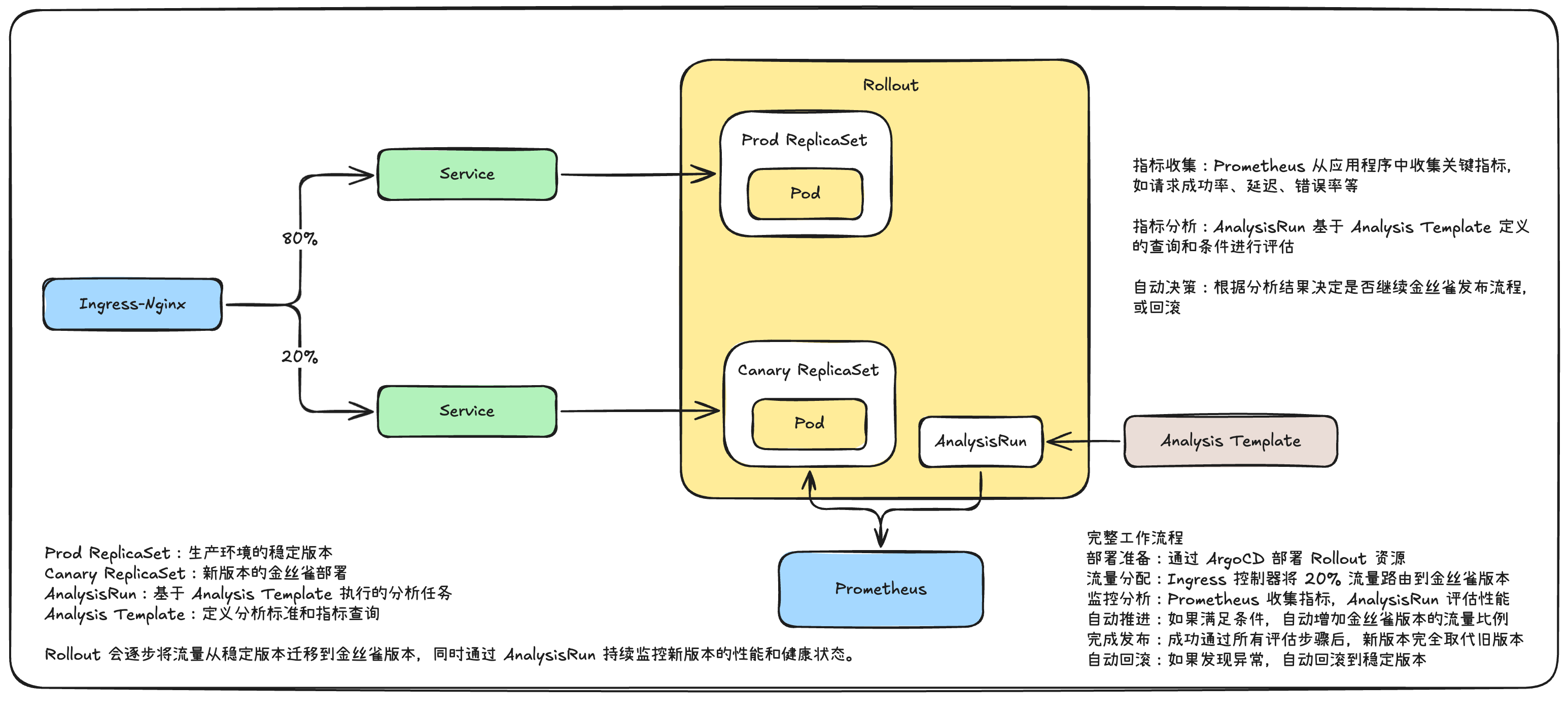
相比较金丝雀发布,自动渐进式交付增加了 Prometheus、Analysis Template 和 AnalysisRun 对象。其中,Analysis Template 定义用于分析的模板,AnalysisRun 是分析模板的实例化,Prometheus 是用来存储指标的数据库。
设计的自动渐进式交付流程会按照下面这张流程图来进行。
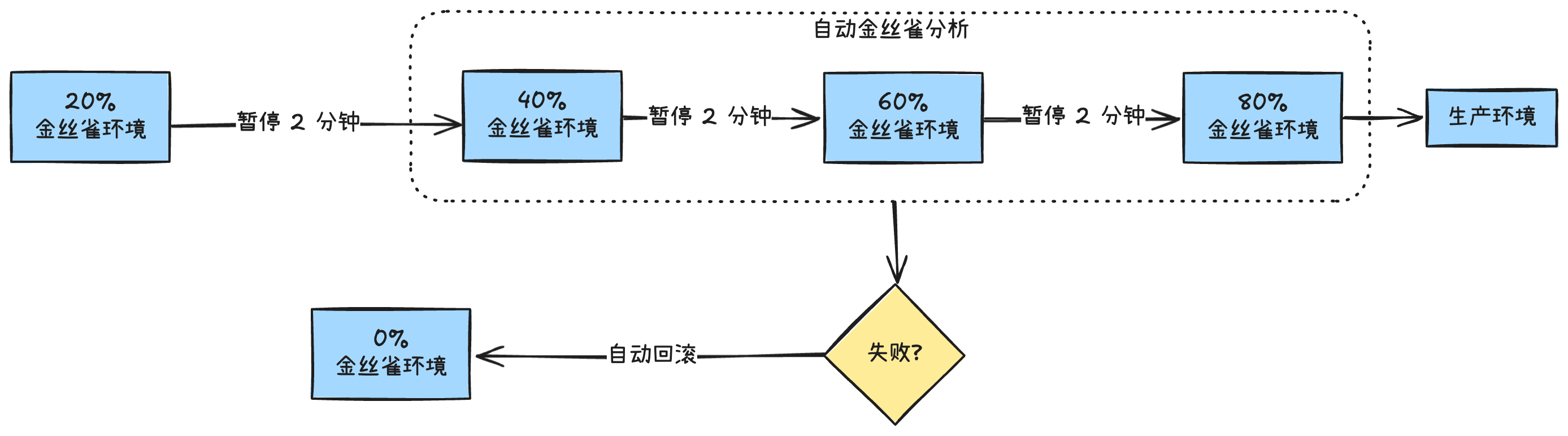
自动渐进式交付开始时,首先会先将金丝雀环境的流量比例设置为 20% 并持续两分钟,然后将金丝雀环境的流量比例设置为 40% 并持续两分钟,然后再以此类推到 60%、80%,直到将金丝雀环境提升为生产环境为止。
从第二个阶段开始,自动金丝雀分析开始运行,在持续运行的过程中,如果金丝雀分析失败,那么金丝雀环境将进行自动回滚。这样就达到了自动渐进式交付的目的。
实践
接下来,我们进入到渐进式交付的实战环节,实战过程大致分成下面几个步骤。
- 创建生产环境,包括 Rollout 对象、Service 和 Ingress。
- [创建用于自动金丝雀分析的 AnalysisTemplate 模板](#创建 Analysis Template)。
- 安装 Prometheus 并配置 Ingress-Nginx。
- 修改镜像版本,启动渐进式交付。
创建生产环境
首先,我们需要创建用于模拟生产环境的 Rollout 对象、Service 和 Ingress。将下面的内容保存为 apd-rollout-with-analysis.yaml 文件。
apiVersion: argoproj.io/v1alpha1
kind: Rollout
metadata:
name: canary-demo
spec:
replicas: 1
selector:
matchLabels:
app: canary-demo
strategy:
canary:
analysis:
templates:
- templateName: success-rate
startingStep: 2
args:
- name: ingress
value: canary-demo
canaryService: canary-demo-canary
stableService: canary-demo
trafficRouting:
nginx:
stableIngress: canary-demo
steps:
- setWeight: 20
- pause:
duration: 2m
- setWeight: 40
- pause:
duration: 2m
- setWeight: 60
- pause:
duration: 2m
- setWeight: 80
- pause:
duration: 2m
template:
metadata:
labels:
app: canary-demo
spec:
containers:
- image: argoproj/rollouts-demo:blue
imagePullPolicy: Always
name: canary-demo
ports:
- containerPort: 8080
name: http
protocol: TCP
resources:
requests:
cpu: 5m
memory: 32Mi
在 canary 字段下面增加了 analysis 字段,它的作用是指定金丝雀分析的模板,模板内容我们会在稍后创建。另外,这里同样使用了 argoproj/rollouts-demo:blue 镜像来模拟生产环境。
然后,使用 kubectl apply 命令将它应用到集群内。
$ kubectl apply -f rollout-with-analysis.yaml
rollout.argoproj.io/canary-demo created接下来,我们还需要创建 Service 对象。在这里,我们可以一并创建生产环境和金丝雀环境所需要用到的 Service ,将下面的内容保存为 apd-canary-demo-service.yaml。
然后,使用 kubectl apply 命令将它应用到集群内。
➜ quartz git:(main*) kb apply -f content/CloudNative/ArgoCD/apd-canary-demo-service.yaml
kbservice/canary-demo unchanged
service/canary-demo-canary unchanged最后,再创建 Ingress 对象。将下面的内容保存为 apd-canary-demo-ingress.yaml 文件。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: canary-demo
labels:
app: canary-demo
annotations:
kubernetes.io/ingress.class: nginx
spec:
rules:
- host: progressive-auto-in-k8s.cheverjohn.me
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: canary-demo
port:
name: http
tls:
- hosts:
- progressive-auto-in-k8s.cheverjohn.me
secretName: progressive-auto-in-k8s-tls
ingressClassName: "nginx"
在这个 Ingress 对象中,指定了 https://progressive-auto-in-k8s.cheverjohn.me 作为访问域名。
然后,使用 kubectl apply 命令将它应用到集群内。
➜ quartz git:(main*) kb apply -f content/CloudNative/ArgoCD/apd-canary-demo-ingress.yaml
kbingress.networking.k8s.io/canary-demo configured创建 Analysis Template
由于我们在 Rollout 对象中指定了名为 success-rate 的金丝雀分析模板,所以我们还需要创建它。将下面的内容保存为 apd-analysis-success.yaml 文件。
apiVersion: argoproj.io/v1alpha1
kind: AnalysisTemplate
metadata:
name: success-rate
spec:
args:
- name: ingress
metrics:
- name: success-rate
interval: 10s
failureLimit: 3
successCondition: result[0] > 0.90
provider:
prometheus:
address: http://kps-prometheus:9090
query: >+
sum(rate(nginx_ingress_controller_requests{ingress="{{args.ingress}}",status!~"[4-5].*"}[60s]))/sum(rate(nginx_ingress_controller_requests{ingress="{{args.ingress}}"}[60s]))
这里我简单介绍一下 AnalysisTemplate 对象字段的含义。首先 spec.args 字段定义了参数,该参数会在后续的 query 语句中使用,它的值是从 Rollout 对象的 canary.analysis.args 字段传递进来的。
这里需要额外注意的是, prometheus 的 address 应该配置正确。不然我一开始就会遇到报错。
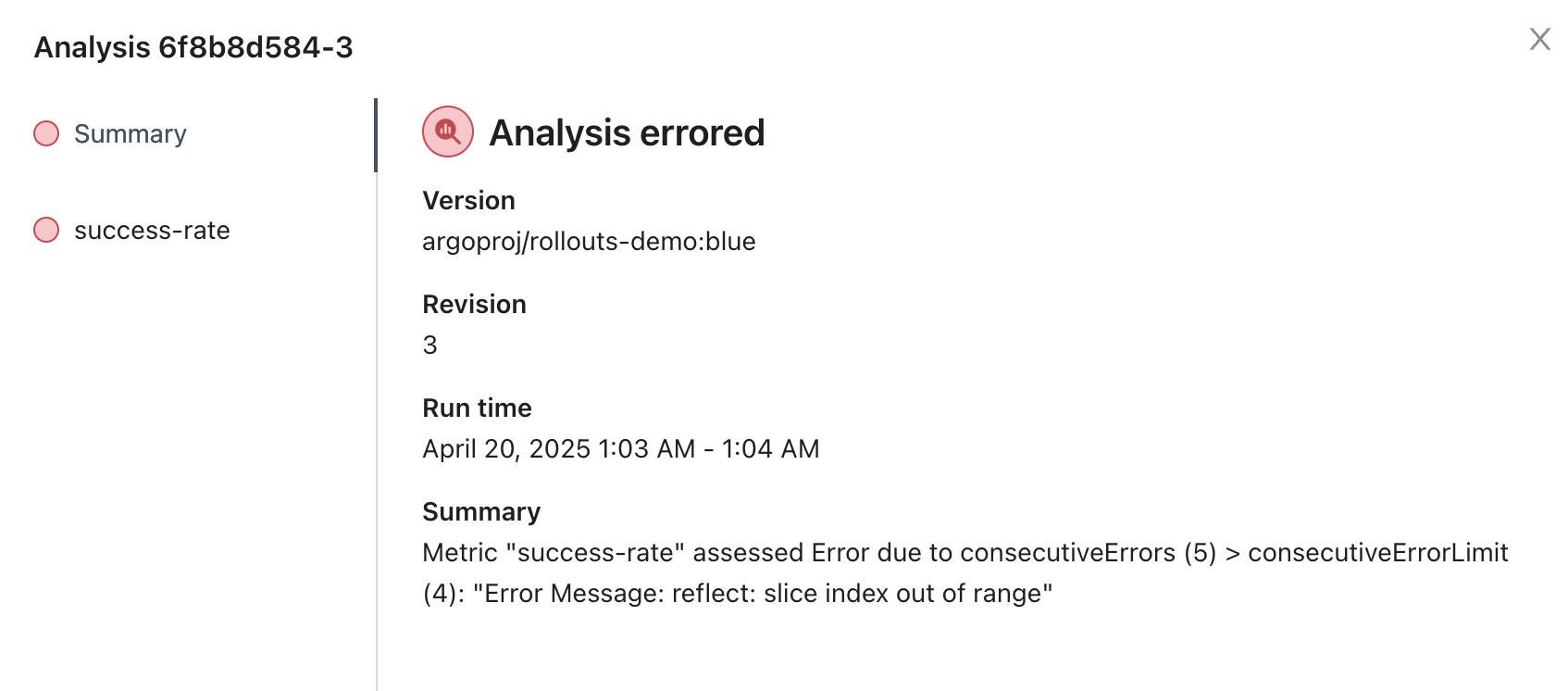
spec.metrics 字段定义了自动分析的相关配置。其中,interval 字段为频率,每 10 秒钟执行一次分析。failureLimit 字段代表“连续 3 次失败则金丝雀分析失败”,此时要执行回滚动作。successCondition 字段代表判断条件,这里的 result[0] 是一个表达式,代表的含义是当查询语句的返回值大于 0.90 时,说明本次金丝雀分析成功了。
最后,spec.metrics.provider 字段定义了分析数据来源于 Prometheus,还定义了 Prometheus Server 的连接地址,我们将在稍后部署 Prometheus。
query 字段是金丝雀分析的查询语句。这条查询语句的含义你可以简单地理解成:在 60 秒内 HTTP 状态码不为 4xx 和 5xx 的请求占所有请求的比例。换句话说,当 HTTP 请求成功的比例大于 0.90 时,代表一次金丝雀分析成功。
访问生产环境
接下来,为了访问生产环境,地址为 https://progressive-auto-in-k8s.cheverjohn.me 。
配置 Ingress-Nginx 和 ServiceMonitor
为了让 Prometheus 能够顺利地获取到 HTTP 请求指标,我们需要打开 Ingress-Nginx Metric 指标端口。并且有 ServiceMonitor。
这一块,因为我本来就是使用 helm upgrade —install 安装的 ingress-nginx。所以我更新了一下安装命令,如下:
helm upgrade --install ingress-nginx ingress-nginx/ingress-nginx \
--version 4.12.1 \
-n ingress-nginx \
--create-namespace \
--set controller.replicaCount=1 \
--set controller.resources.requests.cpu=100m \
--set controller.resources.requests.memory=128Mi \
--set controller.resources.limits.cpu=500m \
--set controller.resources.limits.memory=512Mi \
--set controller.metrics.enabled=true \
--set controller.metrics.serviceMonitor.enabled=true \
--set controller.metrics.serviceMonitor.namespace=ingress-nginx \
--set controller.metrics.serviceMonitor.additionalLabels.release=kps \
--set-string controller.podAnnotations."prometheus\.io/scrape"="true" \
--set-string controller.podAnnotations."prometheus\.io/port"="10254" \
--set global.imageRegistry=harbor.cheverjohn.me/quay.io \
--set grafana.enabled=false \
--set prometheus.enabled=false当把 ServiceMonitor 应用到集群后,Prometheus 会按照标签来匹配 Ingress-Nginx Pod,并且会每 10s 主动拉取一次指标数据,并保存到 Prometheus 时序数据库中。
接下来,我们验证 Prometheus 是否已经成功获取到了 Ingress-Nginx 指标,这将决定自动金丝雀分析是否能成功获取到数据。
我们可以进入 Prometheus 控制台验证是否成功获取了 Ingress-Nginx 指标。首先,使用 kubectl port-forward 命令将 Prometheus 转发到本地。
$ kubectl port-forward service/prometheus-kube-prometheus-prometheus 9090:9090 -n prometheus
Forwarding from 127.0.0.1:9090 -> 9090
Forwarding from [::1]:9090 -> 9090 验证 Ingress-Nginx 指标
验证 Prometheus 是否已经成功获取到了 ingress-nginx 指标,如下:
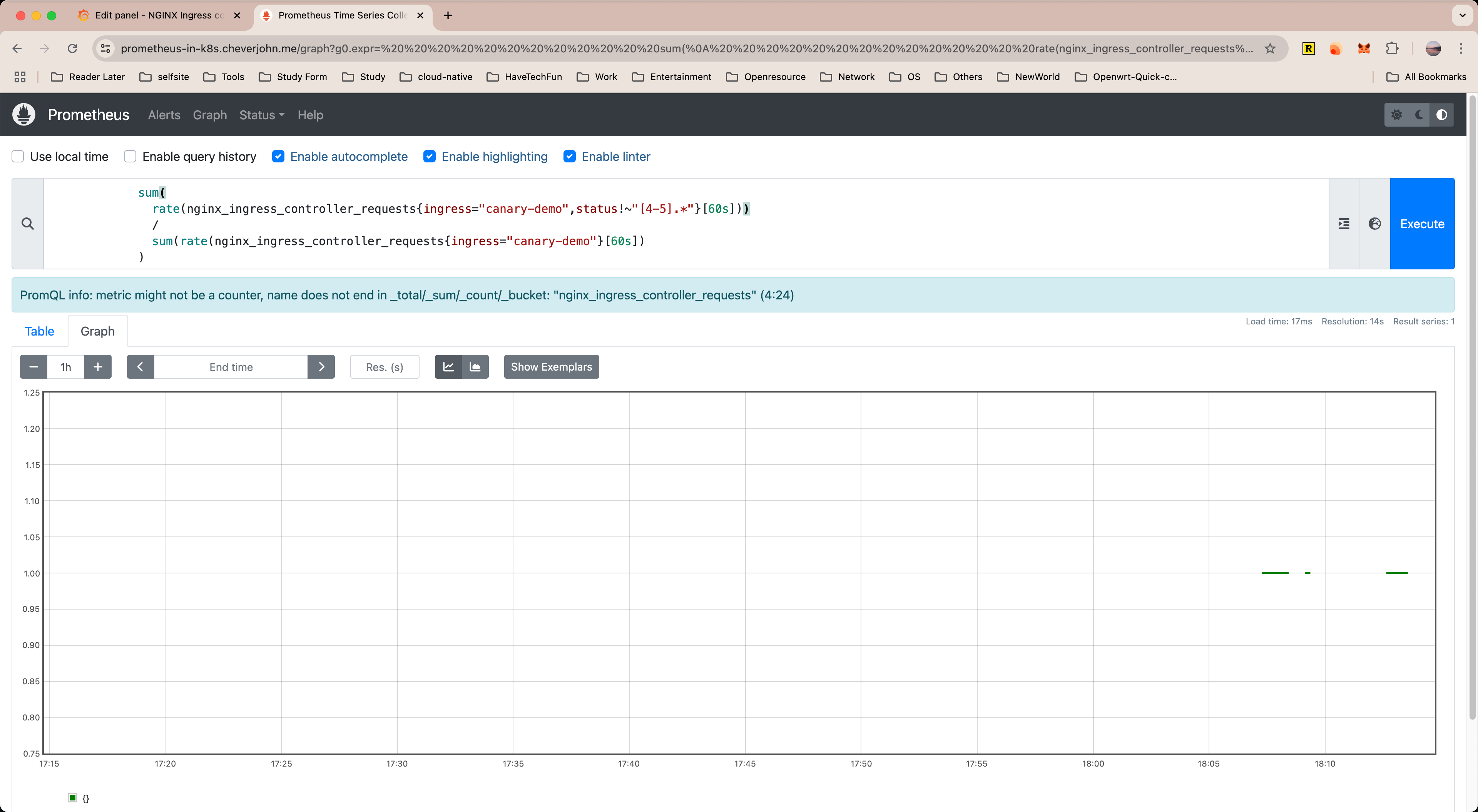
这将决定自动金丝雀分析是否能成功获取到数据。
我的 ingress-nginx 数据如下
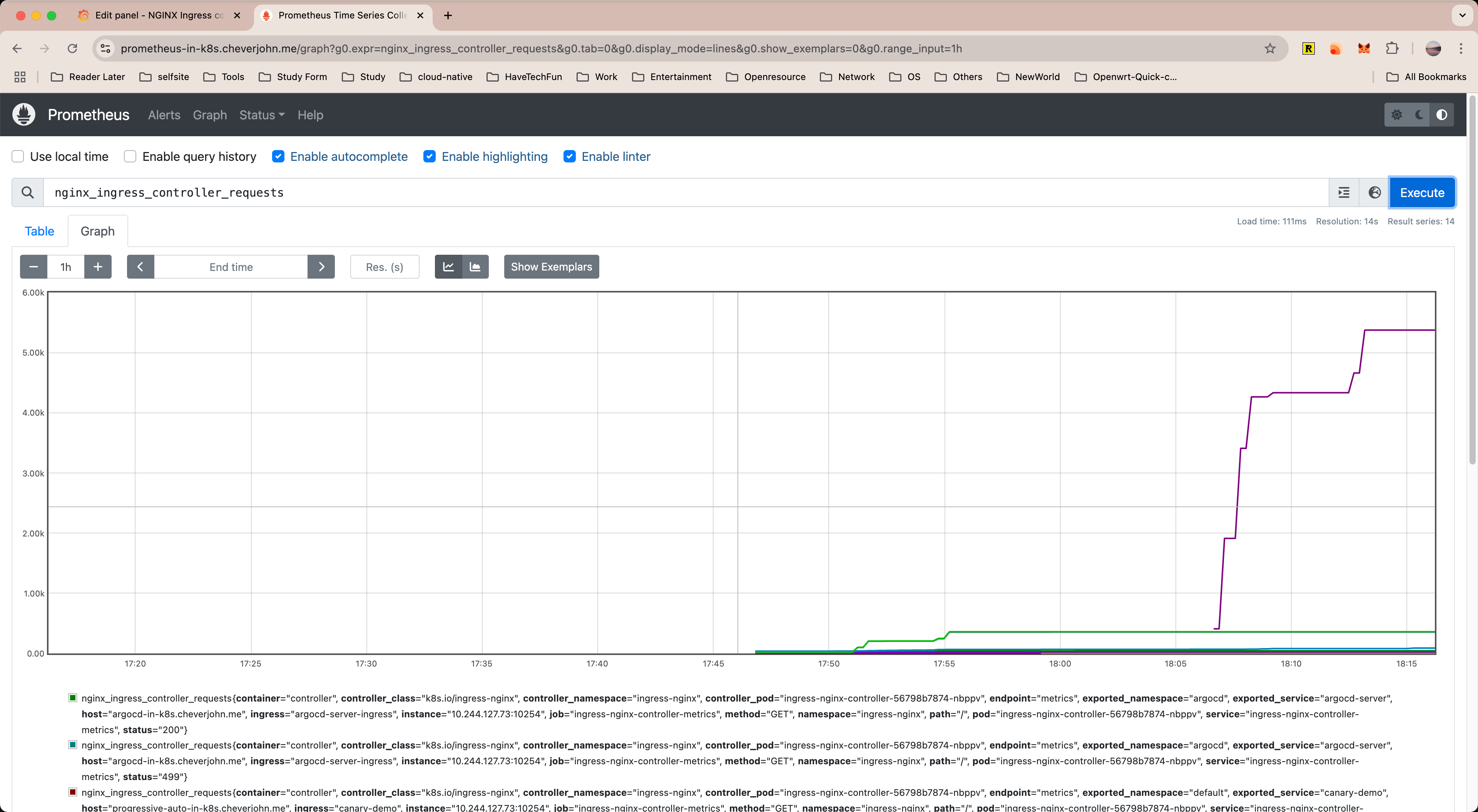
自动渐近式交付实验
现在,所有的准备工作都已经完成了,接下来我们进行自动渐进式交付实验。
让我们重新回忆一下我在前面提到的这张流程图。

在实验过程过程中,我会按照这张流程图分别进行两个实验。
- 自动渐进式交付成功(图中①号链路)。
- 自动渐进式交付失败(图中②号链路)。
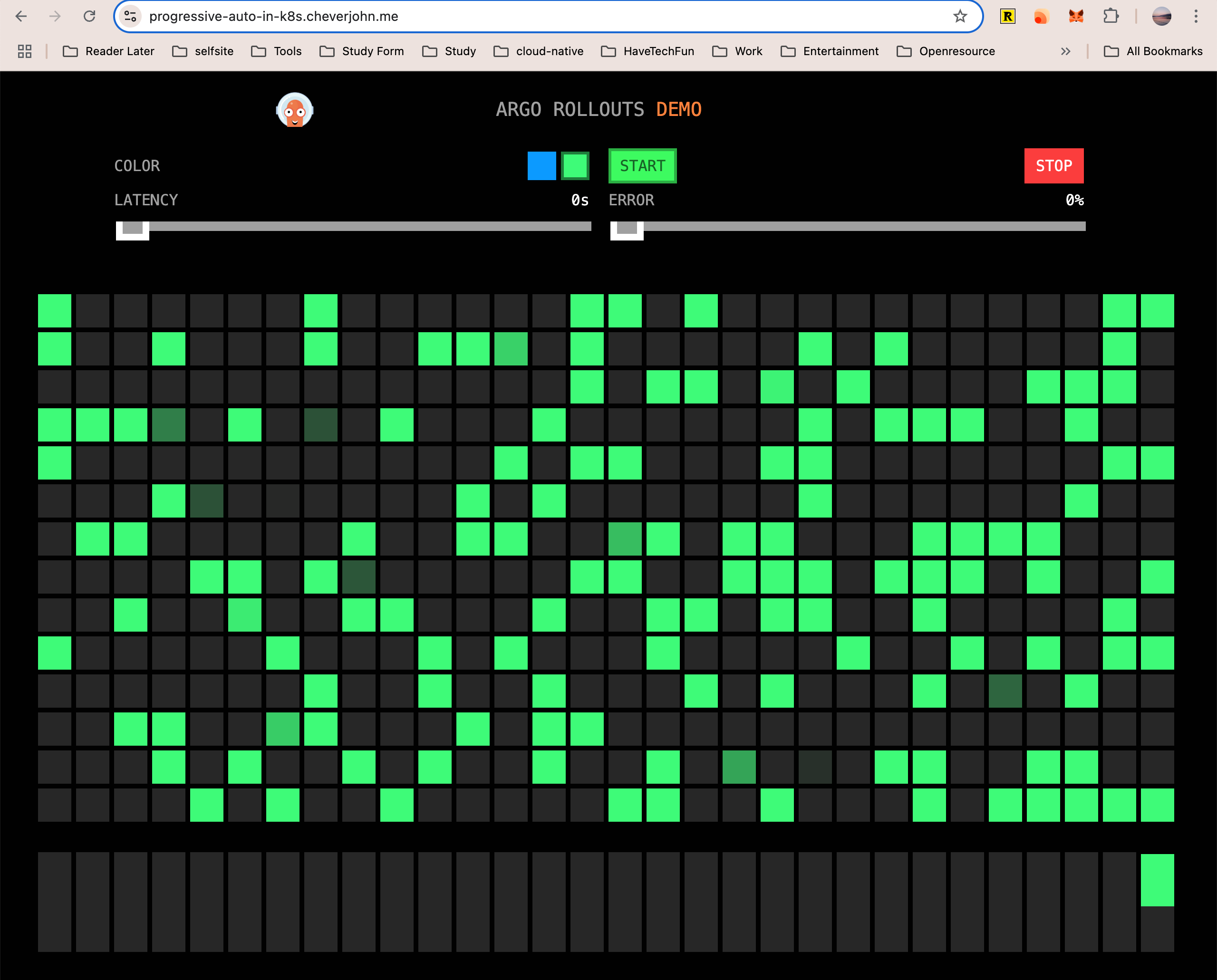
自动渐进式交付成功
接下来,我们进行自动渐进式交付成功的实验。
要开始实验,只要更新 Rollout 对象的镜像版本即可。之前编辑 Rollout 对象并通过 kubectl apply 的方法来更新镜像版本。
这里我们使用另一种更新镜像的方法,通过 Argo Rollout kubectl 插件来更新镜像。
$ kubectl argo rollouts set image canary-demo canary-demo=argoproj/rollouts-demo:blue
rollout "canary-demo" image updated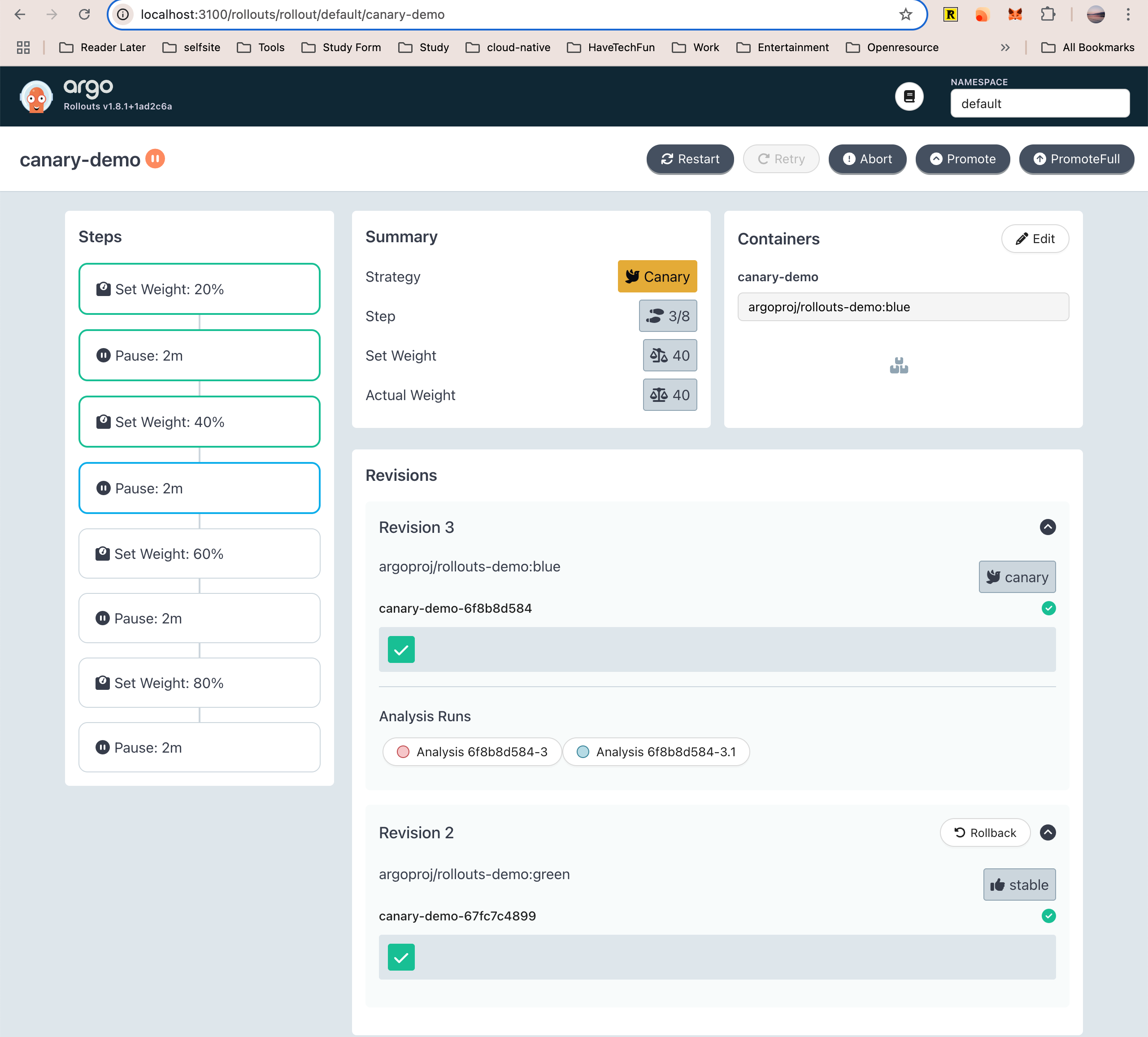
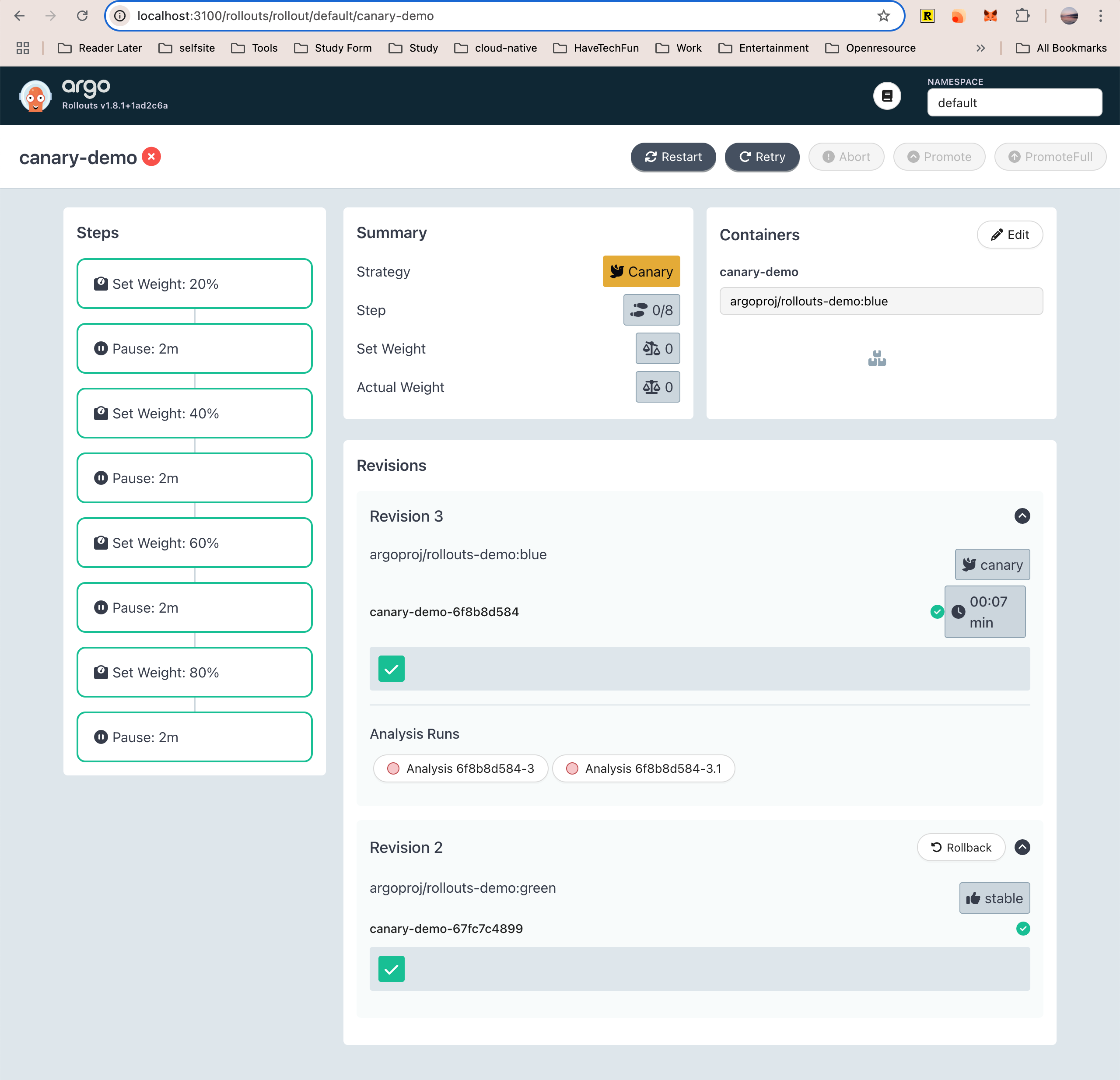
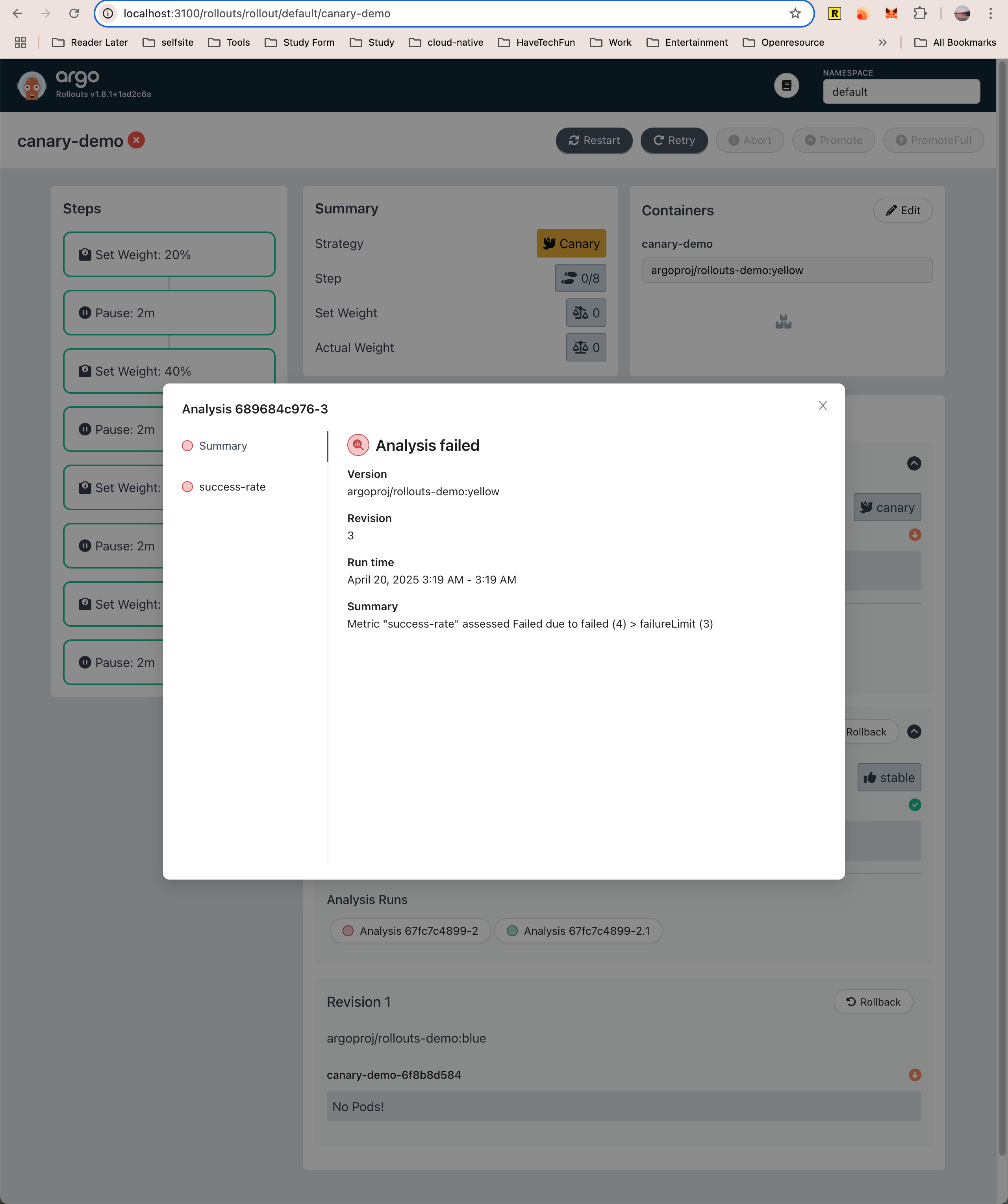
自动渐进式交付失败
在上面的实验中,由于应用返回的 HTTP 状态码都是 200 ,所以金丝雀分析自然是会成功的。
接下来,我们来尝试进行自动渐进式交付失败的实验。
经过了自动渐进式交付成功的实验之后,当前生产环境中的镜像为 argoproj/rollouts-demo:green,我们继续使用 Argo Rollout kubectl 插件来更新镜像,并将镜像版本修改为 yellow 版本。
$ kubectl argo rollouts set image canary-demo canary-demo=argoproj/rollouts-demo:yellow
rollout "canary-demo" image updated接下来,重新返回 https://progressive-auto-in-k8s.cheverjohn.me/ 打开应用,等待一段时间后,你会看到请求开始出现黄色方块,如下图所示。